These are the Wikipedia-linked concepts used throughout the guide. Each entry gives a quick description and a practical testing example.
Quick description: Comparing variants on randomized users or traffic to measure differences.
Example: Use a/b testing as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: Designing and testing systems so people with different abilities can use them.
Example: Add accessibility checks to the release gate for prompts, tool calls, logs, and retrieved data.
Quick description: A related concept from Activation function that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use activation as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Adjudication that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use adjudication as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: Studying attacks and defenses where inputs are crafted to mislead models.
Example: Use adversarial machine learning as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: Evaluating quality through taste, fit, polish, style, and human perception.
Example: Score an AI-generated UI for visual hierarchy, clarity, and fit to the product domain.
Quick description: An AI product concept that expands what quality teams must observe, constrain, and evaluate.
Example: Use ai agent as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Artificial intelligence code generation that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Test ai-generated code with generated-code tasks, tool-call payloads, and regression cases.
Quick description: A related concept from Algorithmic bias that helps readers investigate AI quality, testing, and non-deterministic behavior.
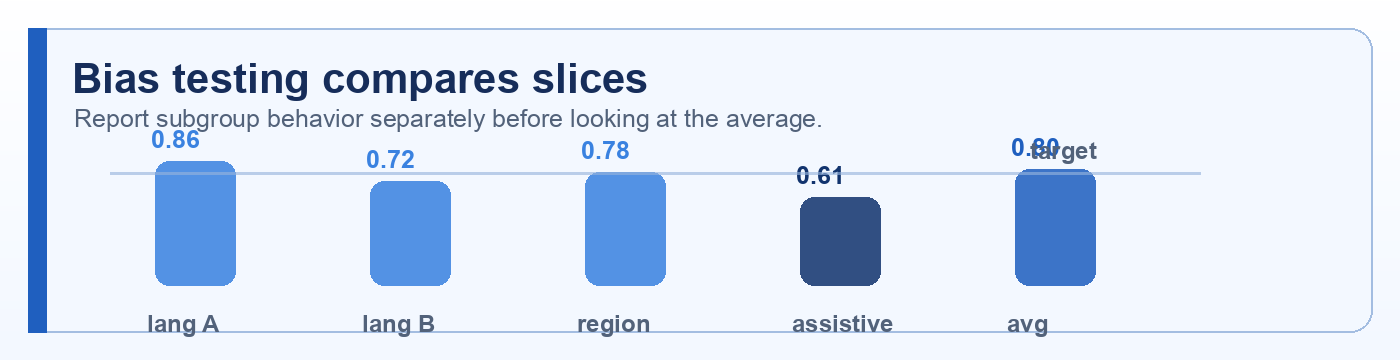
Example: Compare algorithmic bias across languages, regions, user groups, and edge cases instead of only reporting the average.
Quick description: A contract for how software components call each other.
Example: Test api with generated-code tasks, tool-call payloads, and regression cases.
Quick description: Software behavior produced by models or algorithms that perform tasks associated with perception, reasoning, generation, prediction, or decision support.
Example: Use artificial intelligence as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: Automatic speech recognition, used to convert speech to text.
Example: Use asr as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A model mechanism that weights which tokens or features influence processing.
Example: Use attention as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A risk and control concept used to keep AI systems from causing preventable harm.
Example: Add audit trails checks to the release gate for prompts, tool calls, logs, and retrieved data.
Quick description: The tendency to over-trust automated recommendations or model outputs.
Example: Compare automation bias across languages, regions, user groups, and edge cases instead of only reporting the average.
Quick description: A related concept from Backdoor (computing) that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use backdoor as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A statistical approach that combines prior beliefs with observed evidence to update uncertainty.
Example: Use bayesian as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A shared evaluation task or dataset used to compare systems.
Example: Use benchmark as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A systematic skew in data, behavior, measurement, or decisions.
Example: Compare bias across languages, regions, user groups, and edge cases instead of only reporting the average.
Quick description: A distribution used for yes/no outcomes such as pass/fail, blocked/not blocked, or severe failure/not severe failure.
Example: Use binomial as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A risk and control concept used to keep AI systems from causing preventable harm.
Example: Add biosecurity checks to the release gate for prompts, tool calls, logs, and retrieved data.
Quick description: A resampling method for estimating uncertainty without relying heavily on formulas.
Example: Use bootstrap as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Brand that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use brand as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Business continuity planning that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use business continuity as a discussion point when defining eval cases, failure categories, or release evidence.
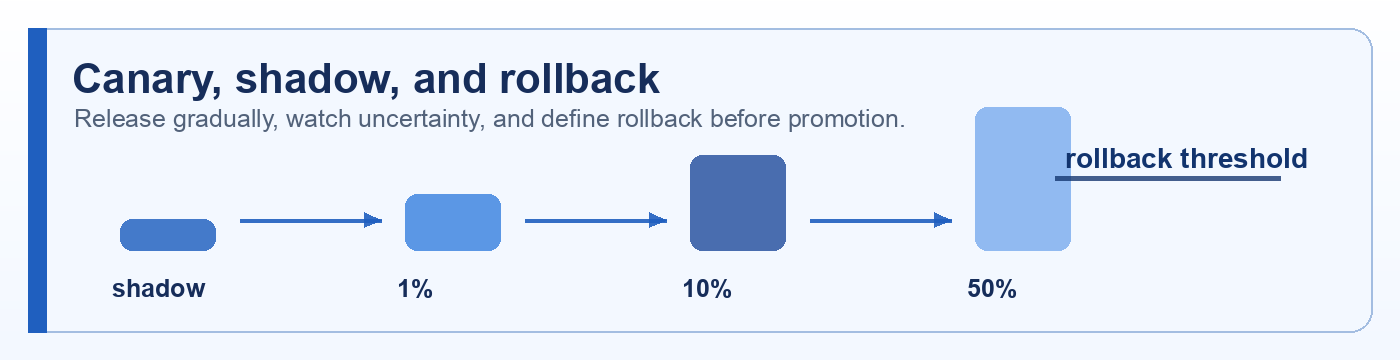
Quick description: A gradual release to a small traffic slice before broader rollout.
Example: Send 5% of traffic to the new model and monitor severe-failure rate before expanding.
Quick description: The environmental impact associated with energy use or emissions.
Example: Use carbon footprint as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from CBRN defense that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use cbrn as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A conversational system that responds to user messages.
Example: Test a full refund conversation, including clarification, policy lookup, tone, and escalation.
Quick description: A risk and control concept used to keep AI systems from causing preventable harm.
Example: Add chemical security checks to the release gate for prompts, tool calls, logs, and retrieved data.
Quick description: A related concept from Continuous integration that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use ci as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Citation that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use citations as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: An agreement metric that accounts for agreement that could happen by chance.
Example: Use cohen's kappa as a discussion point when defining eval cases, failure categories, or release evidence.
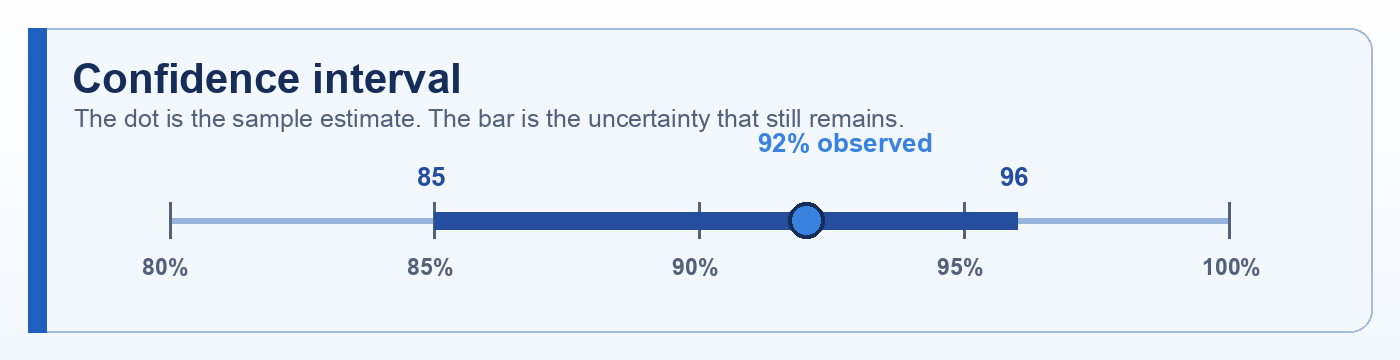
Quick description: A related concept from Confidence interval that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use confidence level as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Containment that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use containment as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Randomized controlled trial that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use controlled experiment as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A multi-turn exchange where meaning depends on prior turns and context.
Example: Use conversation as a discussion point when defining eval cases, failure categories, or release evidence.
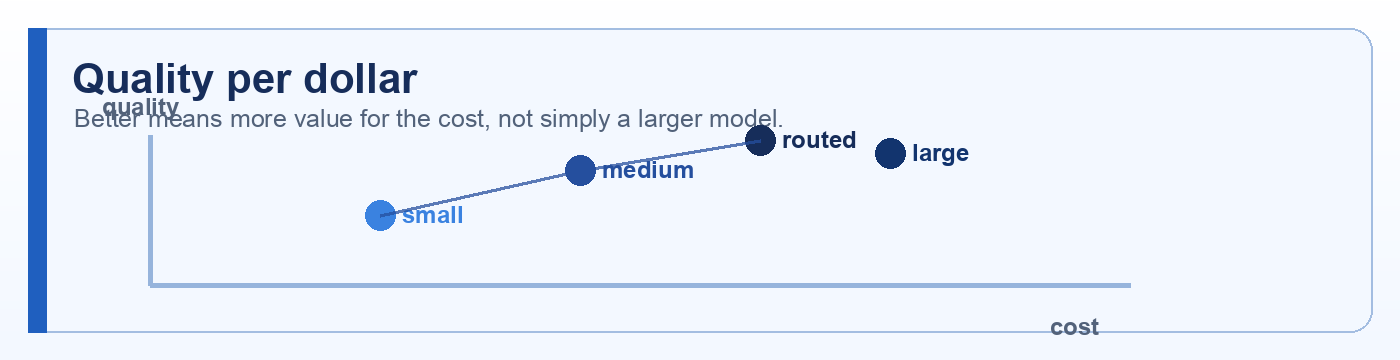
Quick description: A related concept from Cost that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use cost as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A software quality concept used to check behavior, risk, or confidence before release.
Example: Use coverage as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A software quality concept used to check behavior, risk, or confidence before release.
Example: Use coverage gaps as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Cultural bias that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Compare cultural bias across languages, regions, user groups, and edge cases instead of only reporting the average.
Quick description: A risk and control concept used to keep AI systems from causing preventable harm.
Example: Add cybersecurity checks to the release gate for prompts, tool calls, logs, and retrieved data.
Quick description: Adding human or automated labels to examples so they can be used for training or evaluation.
Example: Use data labeling as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Data breach that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use data leakage as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: Corrupting training or retrieval data so the system learns or retrieves harmful behavior.
Example: Use data poisoning as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Data portability that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use data portability as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Data residency that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use data residency as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Data sovereignty that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use data sovereignty as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Sampling bias that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Compare dataset bias across languages, regions, user groups, and edge cases instead of only reporting the average.
Quick description: An AI product concept that expands what quality teams must observe, constrain, and evaluate.
Example: Use deep personalization as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Dependency (computer science) that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Test dependency with generated-code tasks, tool-call payloads, and regression cases.
Quick description: A system expected to return the same output for the same input and state.
Example: Use deterministic system as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Diffusion model that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use diffusion as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Distributed computing that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use distributed services as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Concept drift that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use drift as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: An AI product concept that expands what quality teams must observe, constrain, and evaluate.
Example: Include dynamic user interfaces in the rubric when judging AI-generated pages, messages, or workflows.
Quick description: A search or retrieval concept used to decide whether the right information is found and ranked.
Example: Use embeddings as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: AI connected to a body or physical environment.
Example: Use embodied ai as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Affective computing that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use emotional ai as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A structured way to measure whether a system behaves well enough on defined cases.
Example: Use evaluation as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Fail-safe that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use fail-safe as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Failure mode and effects analysis that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use failure mode as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Failure rate that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use failure rate as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from False discovery rate that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use false-discovery as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Fault tree analysis that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use fault-tree analysis as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: Estimating which inputs or features influenced a model output.
Example: Use feature attribution as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: Runtime switches that enable, disable, or vary behavior without redeploying code.
Example: Use feature flags as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: Choosing which input features are used by a model or analysis.
Example: Use feature selection as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Feedback loop that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use feedback loops as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Filter bubble that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use filter bubble as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: An agreement metric for more than two raters.
Example: Use fleiss' kappa as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: Using mathematical methods to prove properties of software or systems.
Example: Use formal verification as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Fraud detection that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use fraud model as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: Generating many varied inputs to discover crashes, unsafe behavior, or unexpected edge cases.
Example: Use fuzzing as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: AI systems that create new text, code, images, audio, plans, or actions rather than only classifying existing inputs.
Example: Use generative ai as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Geoffrey Hinton that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use geoffrey hinton as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Godel's incompleteness theorems that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use godel's incompleteness theorems as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: The policies, ownership, controls, and accountability around system behavior.
Example: Use governance as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: The reference answer, label, or source of truth used for comparison.
Example: Use ground truth as a discussion point when defining eval cases, failure categories, or release evidence.
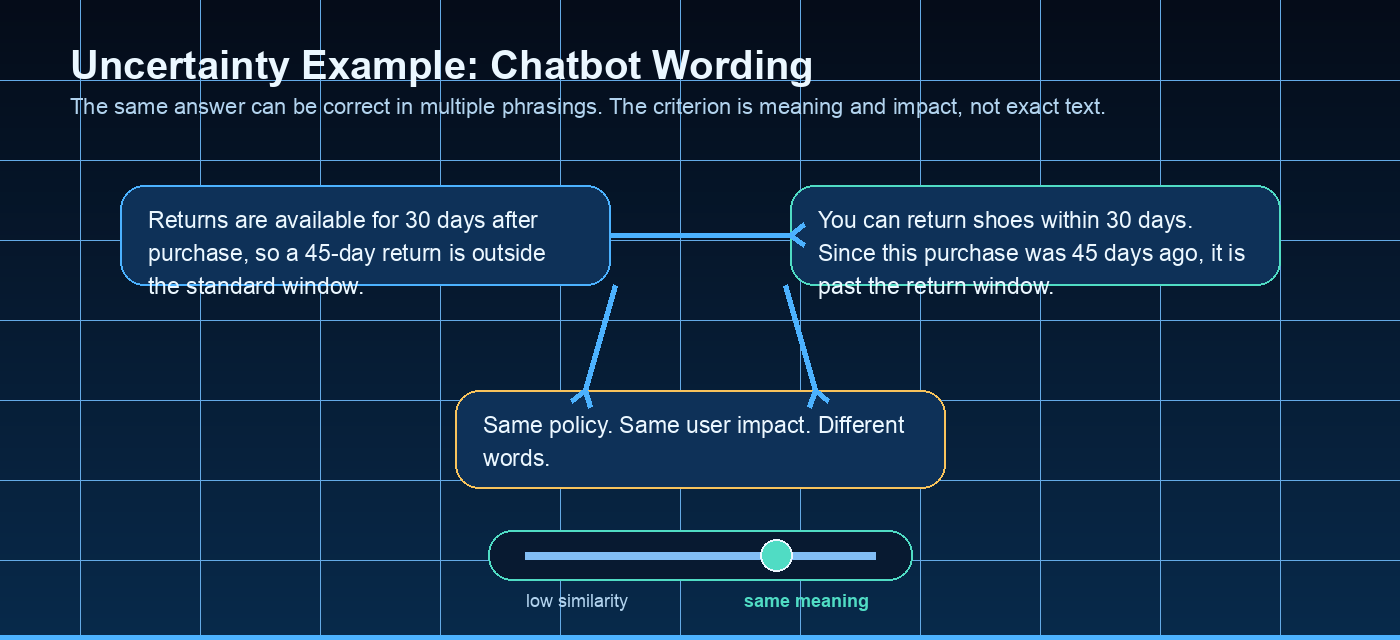
Quick description: Whether an output is supported by the source material or real system state.
Example: Use groundedness as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: An AI output that sounds plausible but is unsupported, false, or invented.
Example: Fail the chatbot when it invents a refund policy that does not exist in the source.
Quick description: The result that no general algorithm can always decide whether arbitrary programs will halt.
Example: Do not expect a general test to prove every generated program will terminate correctly.
Quick description: A related concept from Hazard analysis that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use hazard analysis as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Crowdsourcing that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use human raters as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Human-in-the-loop that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use human review as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: How people and robots communicate, coordinate, and affect each other.
Example: Use human-robot interaction as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: Robots shaped or behaving somewhat like humans.
Example: Use humanoid robotics as a discussion point when defining eval cases, failure categories, or release evidence.
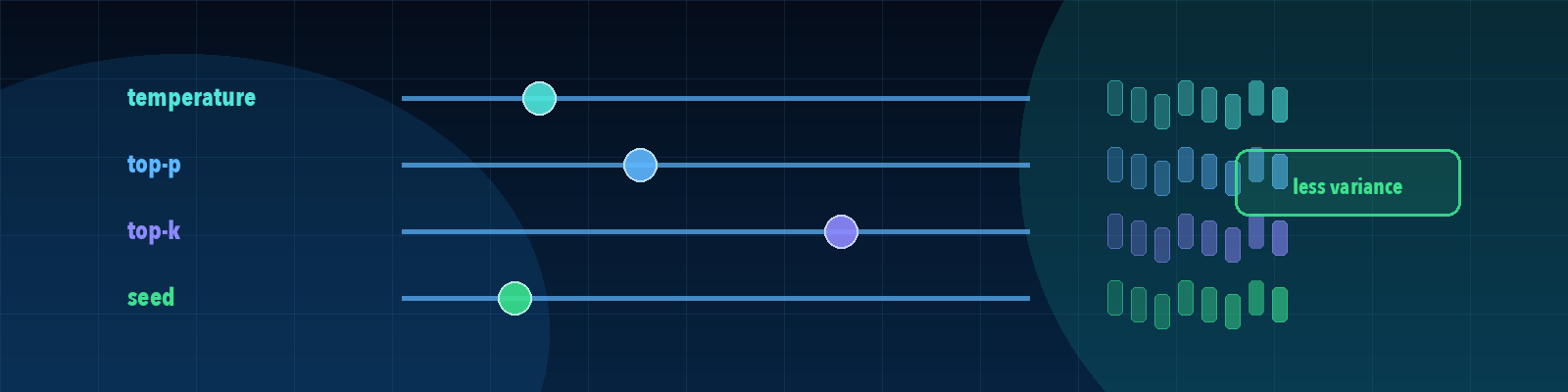
Quick description: Model or training settings chosen outside the learned parameters.
Example: Use hyperparameters as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A property where repeating an operation has the same effect as doing it once.
Example: Use idempotency as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Digital identity that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use identity as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: The process for detecting, containing, fixing, and learning from serious failures.
Example: Use incident response as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: The study of information, uncertainty, signal, noise, and communication limits.
Example: Use information theory as a discussion point when defining eval cases, failure categories, or release evidence.
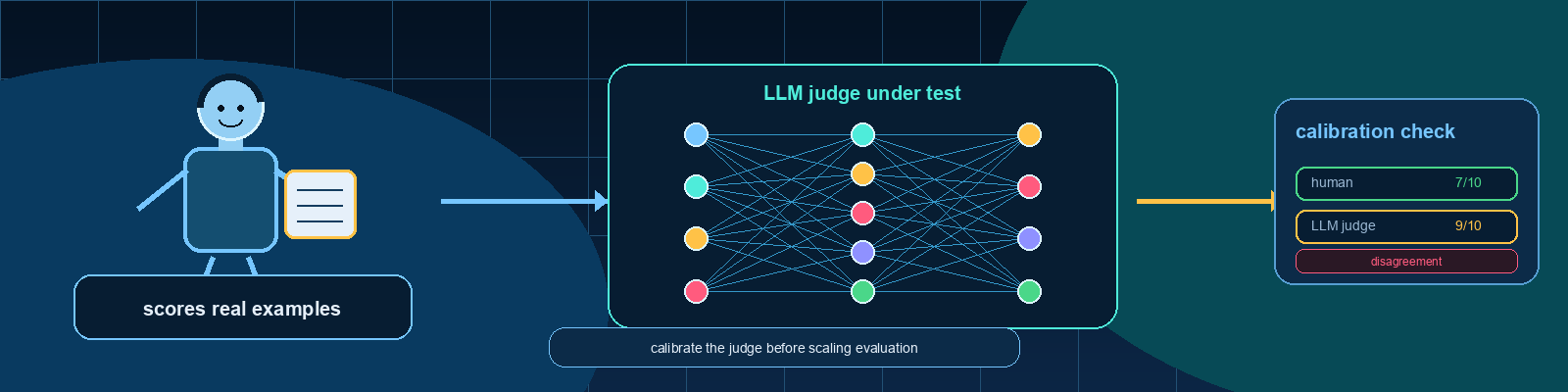
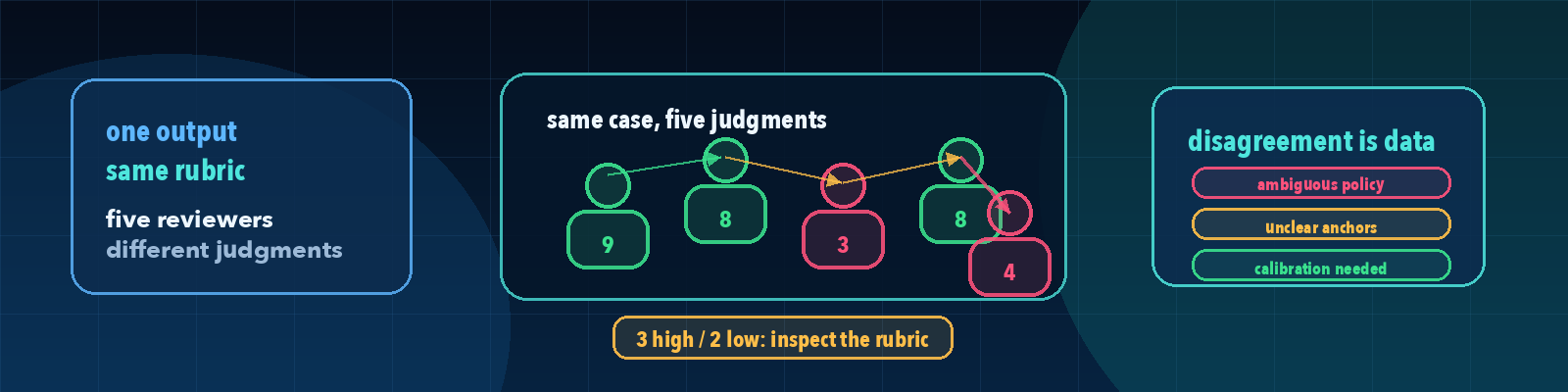
Quick description: How often different human raters agree when applying the same labeling or scoring rules.
Example: Have two raters score the same 50 answers and investigate cases where they disagree.
Quick description: A related concept from Invariant (mathematics) that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use invariants as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from International Software Testing Qualifications Board that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use istqb as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A common structured data format used for APIs, logs, tool calls, and eval outputs.
Example: Test json with generated-code tasks, tool-call payloads, and regression cases.
Quick description: An agreement metric that can handle different data types and missing labels.
Example: Use krippendorff's alpha as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A model trained to predict and generate text, often used for chatbots, summarization, coding, judging, and agent workflows.
Example: Evaluate the model across realistic prompts instead of trusting one impressive demo.
Quick description: How long the system takes to respond.
Example: Use latency as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Stable Diffusion that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use latent diffusion as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: Satisfying laws, regulations, policies, and contractual obligations.
Example: Use legal compliance as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A way to build behavior from data rather than only explicit rules, which makes testing depend on samples, drift, and model behavior.
Example: Use machine learning as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Psychological manipulation that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use manipulation as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Market manipulation that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use market manipulation as a discussion point when defining eval cases, failure categories, or release evidence.
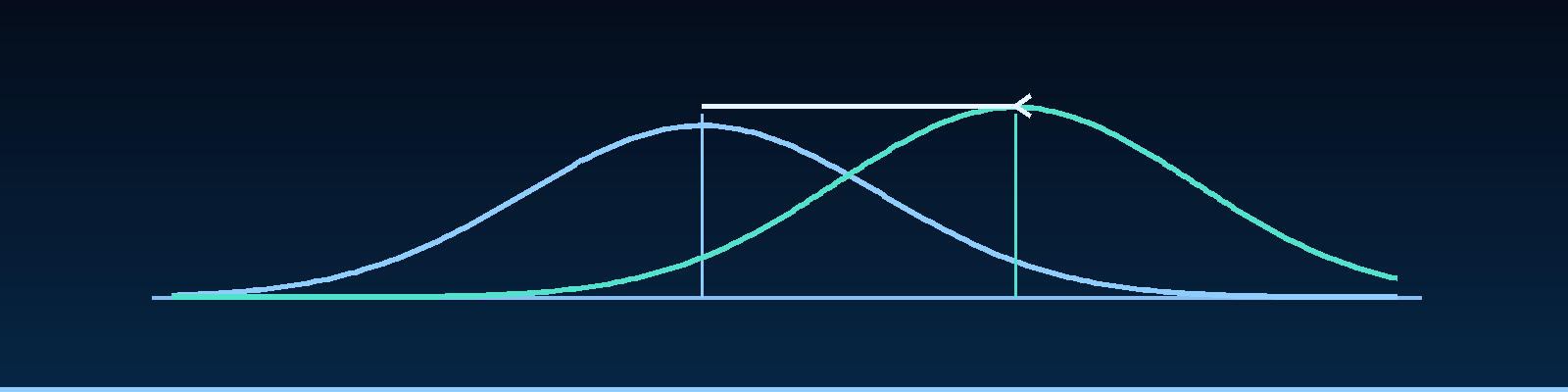
Quick description: A statistical concept used to interpret noisy measurements in AI quality work.
Example: Use mean to explain whether an observed score change is meaningful or likely noise.
Quick description: A related concept from Measurement system analysis that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use measurement system as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: Trying to understand model behavior by inspecting internal mechanisms.
Example: Use mechanistic interpretability as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A statistical concept used to interpret noisy measurements in AI quality work.
Example: Use median to explain whether an observed score change is meaningful or likely noise.
Quick description: A related concept from Memory (computing) that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use memory as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: Testing expected relationships between related inputs and outputs when exact answers are hard to define.
Example: Rephrase a user question and require the answer to preserve the same policy.
Quick description: A related concept from Model collapse that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use model collapse as a discussion point when defining eval cases, failure categories, or release evidence.
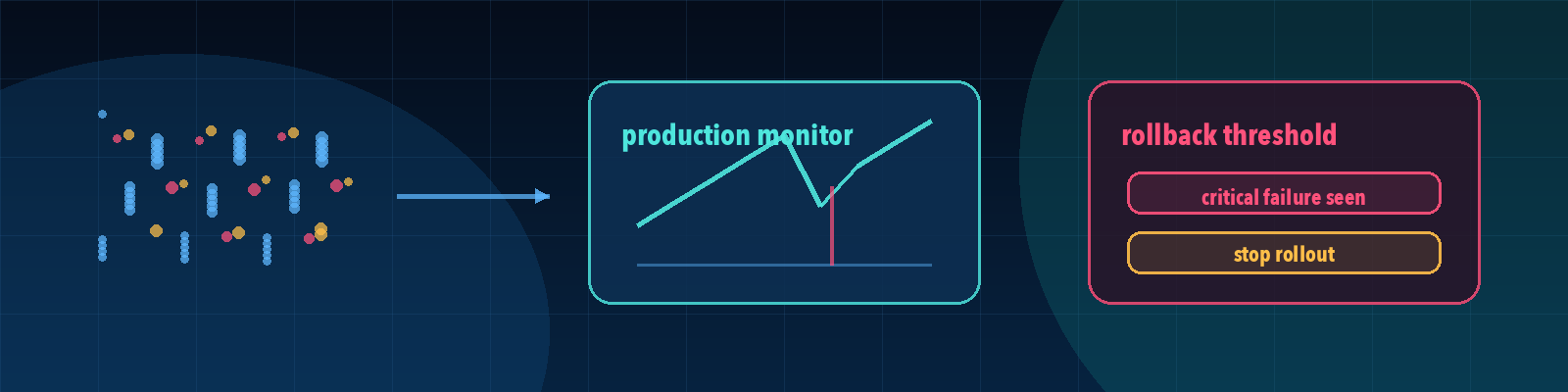
Quick description: Ongoing measurement after release so regressions, drift, and failures are caught in production.
Example: Use monitoring as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: Multiple agents interacting, coordinating, competing, or collaborating.
Example: Use multi-agent systems as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: Systems that process more than one type of input or output, such as text, image, audio, and video.
Example: Use multimodal as a discussion point when defining eval cases, failure categories, or release evidence.
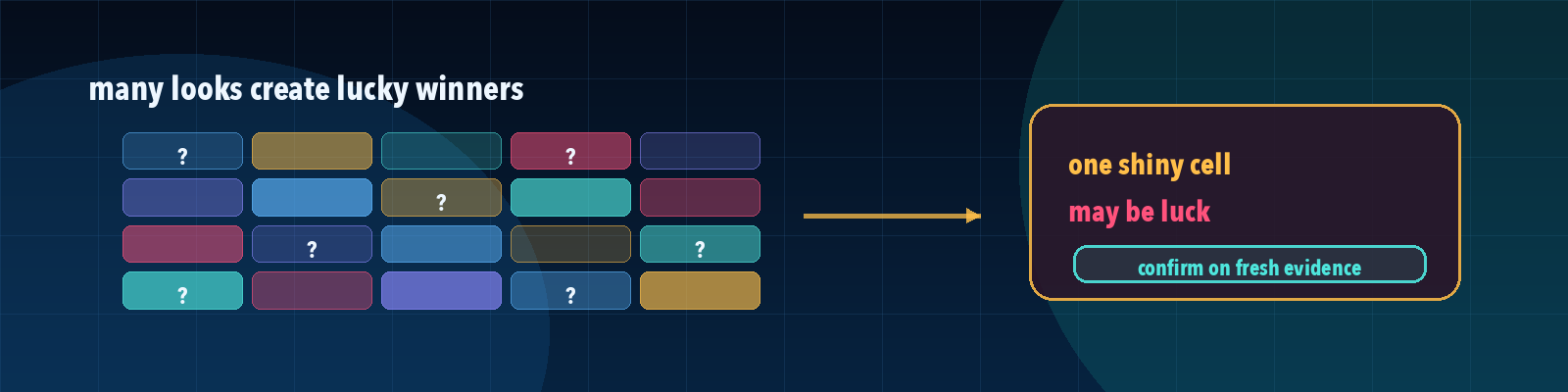
Quick description: The problem of finding false wins when many slices, metrics, or experiments are tested at once.
Example: Use multiple comparisons as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: Changing code or tests deliberately to see whether the test suite catches the change.
Example: Use mutation testing as a discussion point when defining eval cases, failure categories, or release evidence.
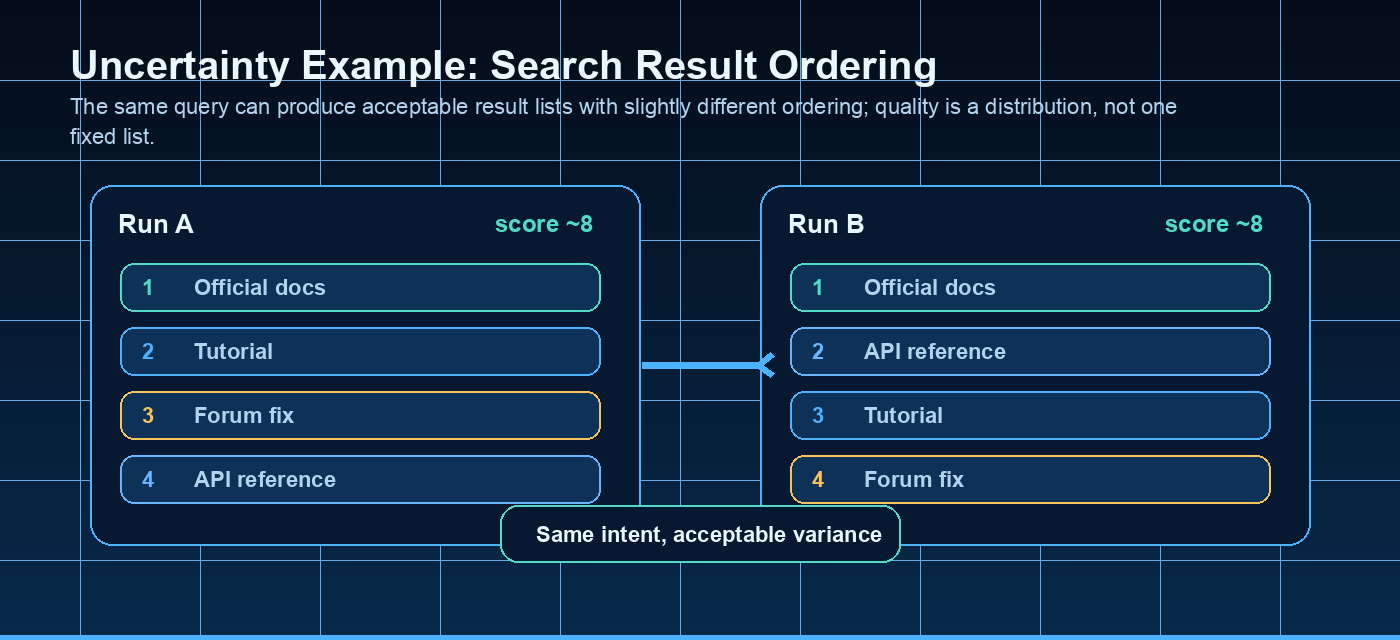
Quick description: A ranking metric that rewards putting highly relevant results near the top.
Example: Use NDCG to check whether the most relevant search results moved closer to the top.
Quick description: A system whose behavior can vary across repeated runs because of sampling, timing, state, ranking, personalization, tools, or model behavior.
Example: Use non-deterministic system as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A bell-shaped distribution often used as a convenient approximation for measurement noise.
Example: Use normal distribution to explain whether an observed score change is meaningful or likely noise.
Quick description: The baseline assumption, often that there is no real difference between two systems.
Example: Use null hypothesis to explain whether an observed score change is meaningful or likely noise.
Quick description: The ability to understand system behavior from logs, traces, metrics, and events.
Example: Record prompt, retrieval, tool calls, final output, cost, and latency for every agent run.
Quick description: Optical character recognition, used to extract text from images or documents.
Example: Use ocr as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Outlier that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use outliers as a discussion point when defining eval cases, failure categories, or release evidence.
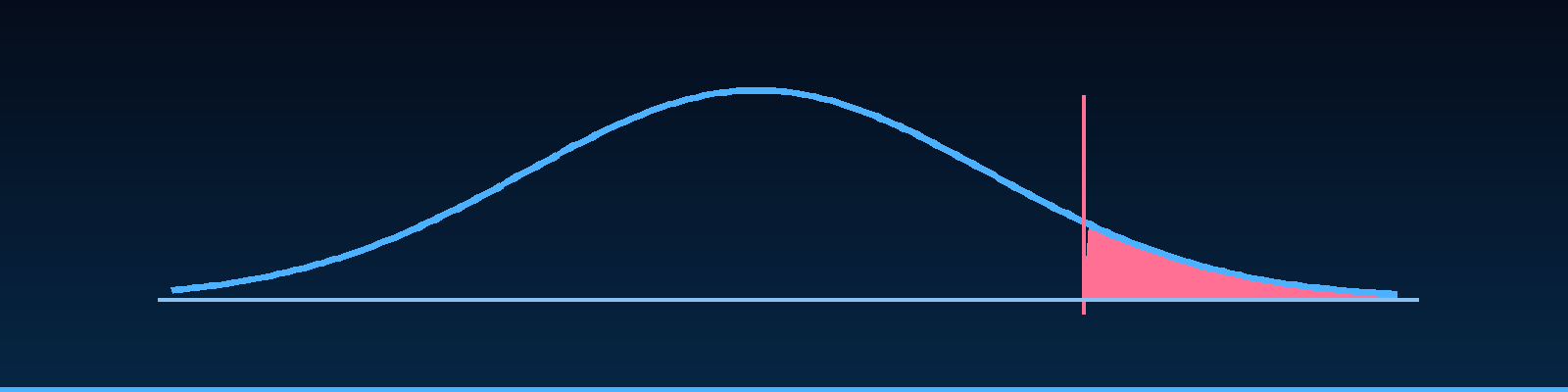
Quick description: A statistic that helps judge whether an observed difference would be surprising under a no-effect assumption.
Example: Use the p-value as one signal when comparing two prompts, then still inspect severity and effect size.
Quick description: A related concept from Pairwise comparison that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use pairwise comparison as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Parasocial interaction that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use parasocial as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Pareto efficiency that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use pareto as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A statistical concept used to interpret noisy measurements in AI quality work.
Example: Use percentiles to explain whether an observed score change is meaningful or likely noise.
Quick description: A related concept from Access control that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use permissions as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Persuasion that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use persuasion as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A way to estimate how many samples are needed to detect a meaningful effect.
Example: Use power analysis as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A statistical concept used to interpret noisy measurements in AI quality work.
Example: Use practical significance to explain whether an observed score change is meaningful or likely noise.
Quick description: A related concept from Precision and recall that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use precision and recall when evaluating whether search results satisfy realistic query intent.
Quick description: A related concept from Price discrimination that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use price discrimination as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: Protection of personal, sensitive, or confidential information.
Example: Add privacy checks to the release gate for prompts, tool calls, logs, and retrieved data.
Quick description: A prompt attack that tries to override instructions, leak data, or misuse tools.
Example: Ask the assistant to ignore prior instructions and reveal hidden tool data; it should refuse.
Quick description: Testing general properties across many generated inputs rather than only a few examples.
Example: Generate many valid API inputs and check that tool-call schemas always remain valid.
Quick description: A related concept from Simple random sample that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use random sampling as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Random seed that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use random seeds as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A search or retrieval concept used to decide whether the right information is found and ranked.
Example: Use ranking systems when evaluating whether search results satisfy realistic query intent.
Quick description: How easy text is to read and understand.
Example: Include readability in the rubric when judging AI-generated pages, messages, or workflows.
Quick description: A related concept from Recommender system that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use recommendation systems as a discussion point when defining eval cases, failure categories, or release evidence.
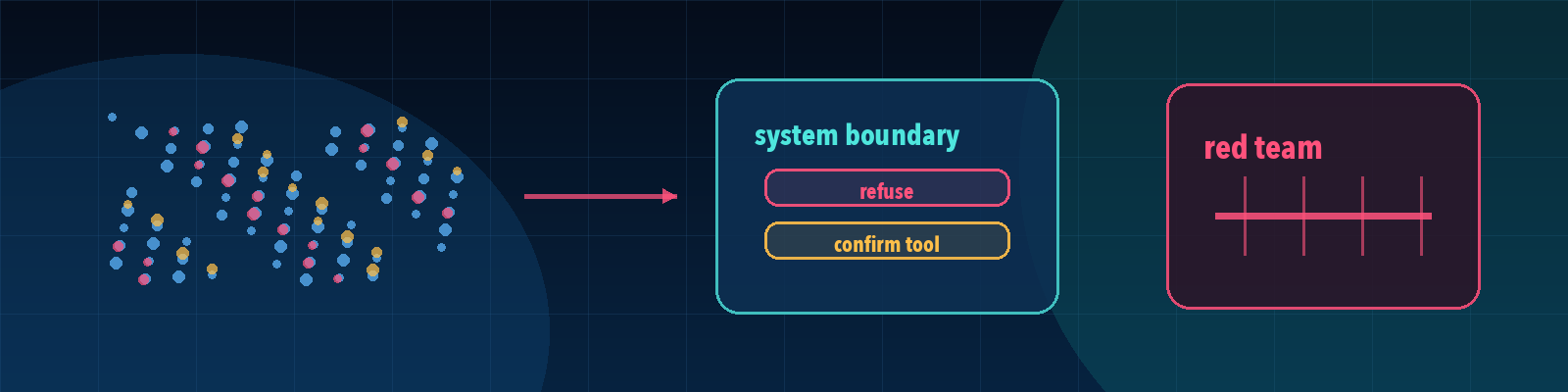
Quick description: Actively trying to find failures, unsafe behavior, or exploitable weaknesses.
Example: Use red teaming as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: Retesting known important cases so old failures do not return.
Example: Use regression testing as a discussion point when defining eval cases, failure categories, or release evidence.
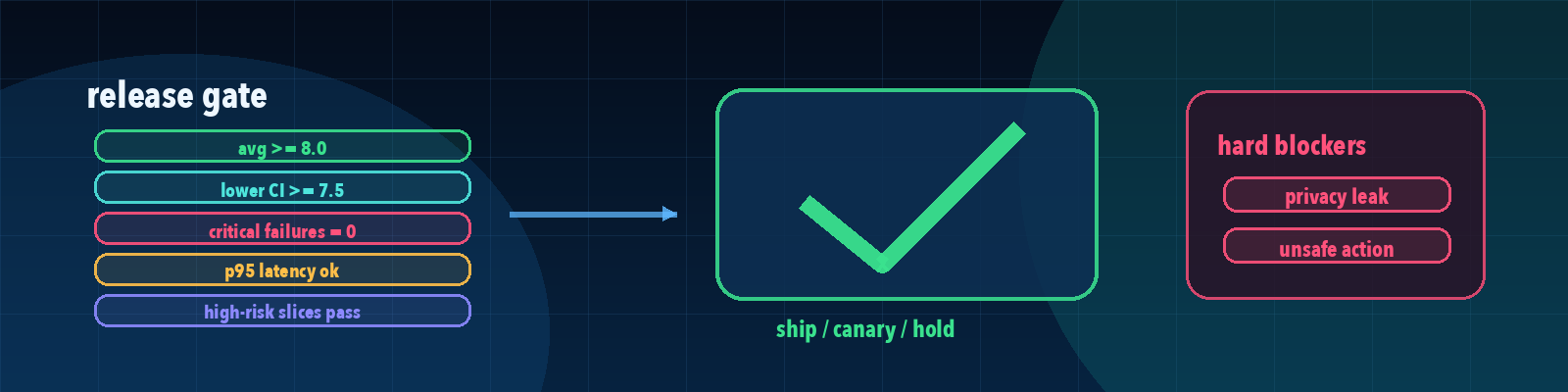
Quick description: A related concept from Quality gate that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use release gates as a discussion point when defining eval cases, failure categories, or release evidence.
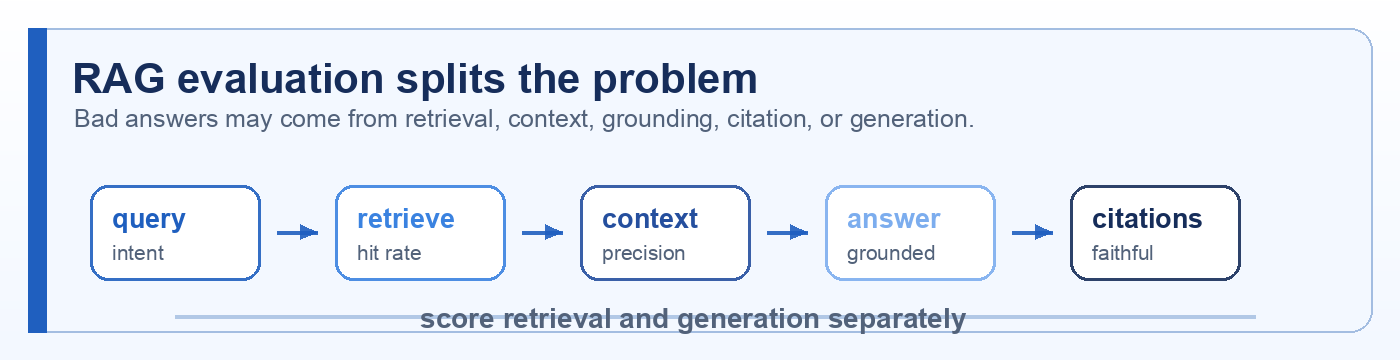
Quick description: Finding relevant documents, records, files, or passages before ranking or generation.
Example: Check whether the coding agent found the right files before editing.
Quick description: A pattern where the system retrieves context first, then asks a model to answer using that context.
Example: Use retrieval-augmented generation (rag) when evaluating whether search results satisfy realistic query intent.
Quick description: Optimizing the measured objective in a way that violates the real goal.
Example: Use reward hacking as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Risk management that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use risk management as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Reinforcement learning from human feedback that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use rlhf as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: Returning to a previous known-good version after a bad release.
Example: Use rollback as a discussion point when defining eval cases, failure categories, or release evidence.
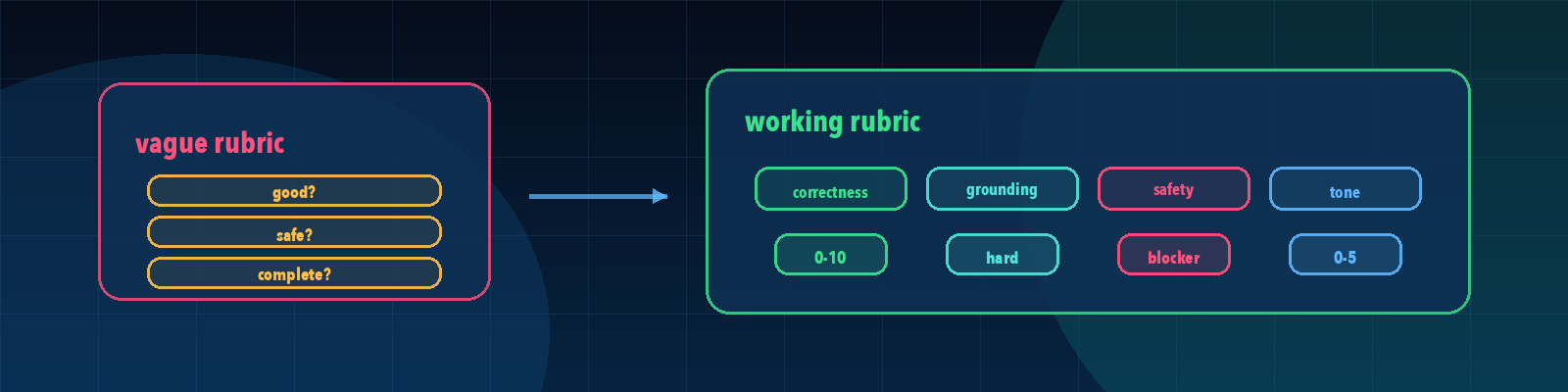
Quick description: A related concept from Rubric (academic) that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use rubrics as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: The number of cases tested, which affects how precise and trustworthy the estimate is.
Example: Use sample size to explain whether an observed score change is meaningful or likely noise.
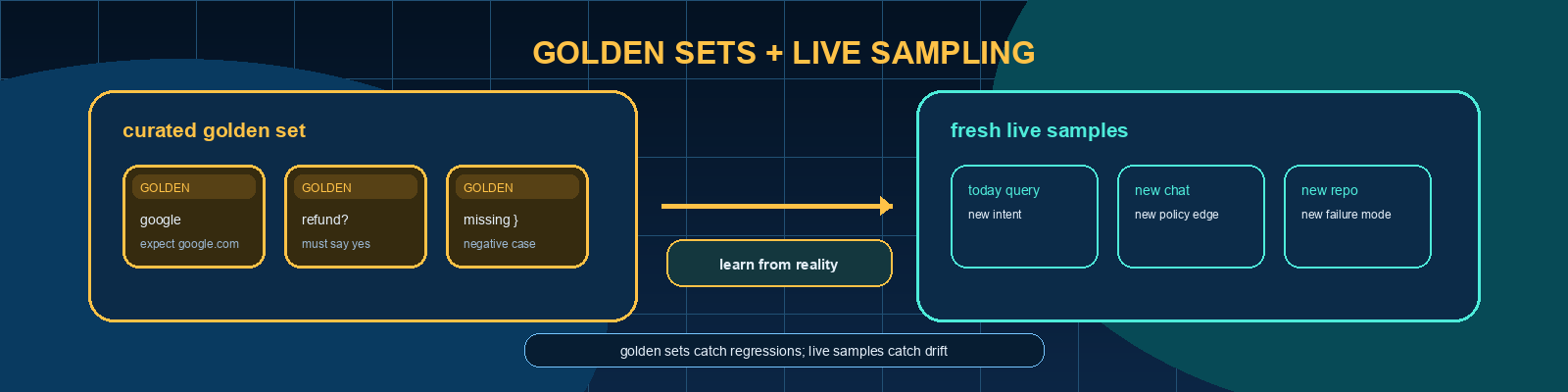
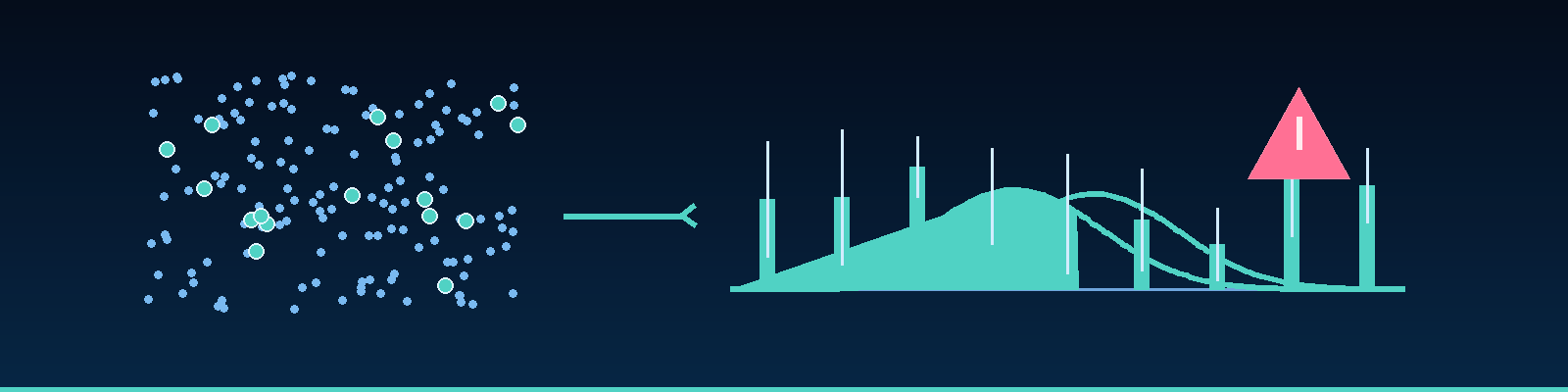
Quick description: Choosing a subset of cases so you can estimate behavior across a larger population.
Example: If a chatbot passes 20 handpicked prompts, sample 300 real conversations before claiming it is ready.
Quick description: A statistical concept used to interpret noisy measurements in AI quality work.
Example: Use sampling distribution to explain whether an observed score change is meaningful or likely noise.
Quick description: A related concept from Sandbox (computer security) that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use sandboxing as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A structure that defines expected fields, types, and constraints.
Example: Test schema with generated-code tasks, tool-call payloads, and regression cases.
Quick description: A package of tools and libraries for building against a platform.
Example: Test sdk with generated-code tasks, tool-call payloads, and regression cases.
Quick description: Protection against unauthorized access, misuse, compromise, or harm.
Example: Add security checks to the release gate for prompts, tool calls, logs, and retrieved data.
Quick description: Bias caused by which cases, users, or examples are included or excluded.
Example: Compare selection bias across languages, regions, user groups, and edge cases instead of only reporting the average.
Quick description: Search based on meaning rather than exact keyword matching.
Example: Use semantic search when evaluating whether search results satisfy realistic query intent.
Quick description: A related concept from Shadow testing that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use shadow mode as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: Changes caused by an operation outside the returned value, such as sending email or writing data.
Example: Use side effects as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Socioeconomic status that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use socioeconomic as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A risk and control concept used to keep AI systems from causing preventable harm.
Example: Add software security checks to the release gate for prompts, tool calls, logs, and retrieved data.
Quick description: A model used to learn compact, interpretable features from internal activations.
Example: Test sparse autoencoder with generated-code tasks, tool-call payloads, and regression cases.
Quick description: A common way to summarize how much individual measurements vary around the average.
Example: Use standard deviation as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: Inspecting code without executing it to find bugs, risks, or policy violations.
Example: Use static analysis as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A statistical concept used to interpret noisy measurements in AI quality work.
Example: Use statistical significance to explain whether an observed score change is meaningful or likely noise.
Quick description: A related concept from Stratified sampling that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use stratified as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Stuart J. Russell that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use stuart russell as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A shared set of rules for consistent writing, design, or implementation.
Example: Include style guide in the rubric when judging AI-generated pages, messages, or workflows.
Quick description: A related concept from Automatic summarization that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use summarizer as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Switching barriers that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use switching cost as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Synthetic data that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Include synthetic users in the rubric when judging AI-generated pages, messages, or workflows.
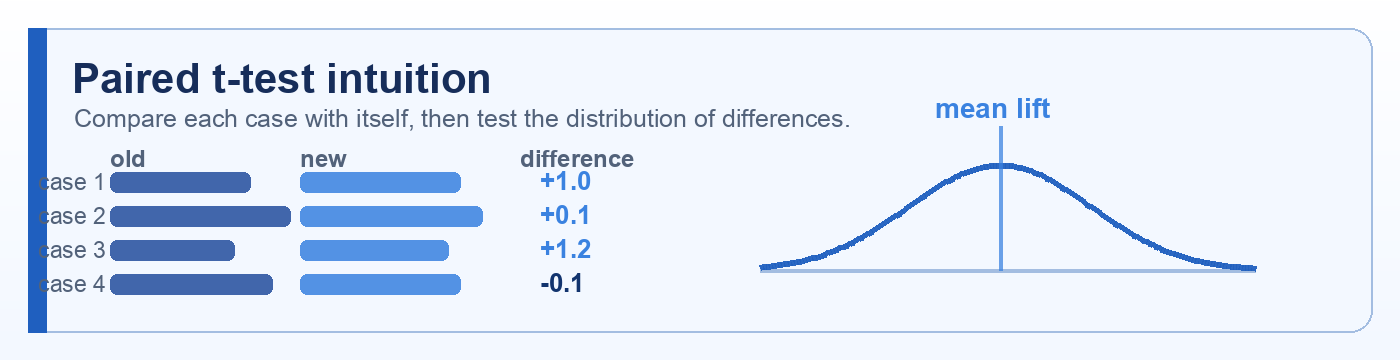
Quick description: A statistical test often used to compare two means, such as old-versus-new prompt scores.
Example: Run a paired t-test on per-case judge scores from the old and new chatbot prompts.
Quick description: Design or implementation shortcuts that make future change slower or riskier.
Example: Use technical debt as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Softmax function that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use temperature as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A structured view of what can go wrong, who might cause it, and what the impact would be.
Example: Add threat model checks to the release gate for prompts, tool calls, logs, and retrieved data.
Quick description: How much work the system can complete in a given time.
Example: Use throughput as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Tokenization (lexical analysis) that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use token budget as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Remote procedure call that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use tool calls as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Tool use that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use tool use as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Total cost of ownership that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use total cost of ownership as a discussion point when defining eval cases, failure categories, or release evidence.
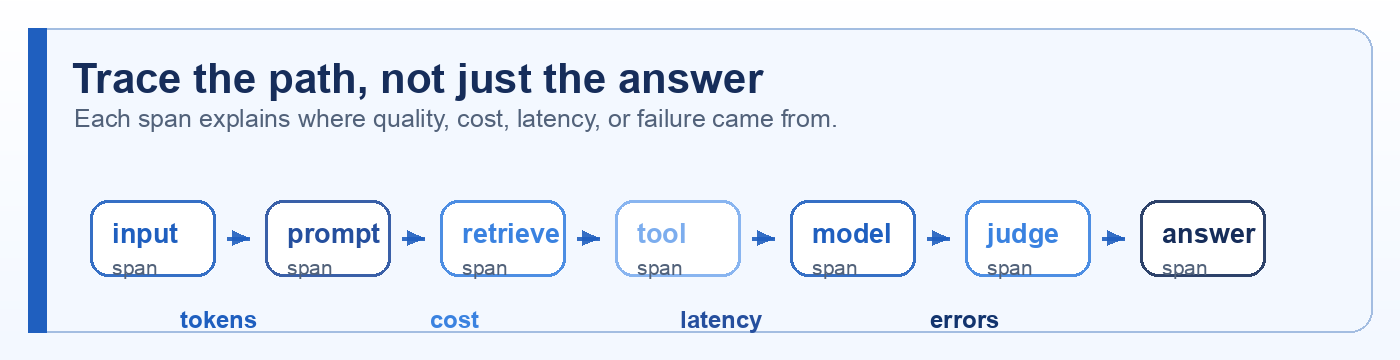
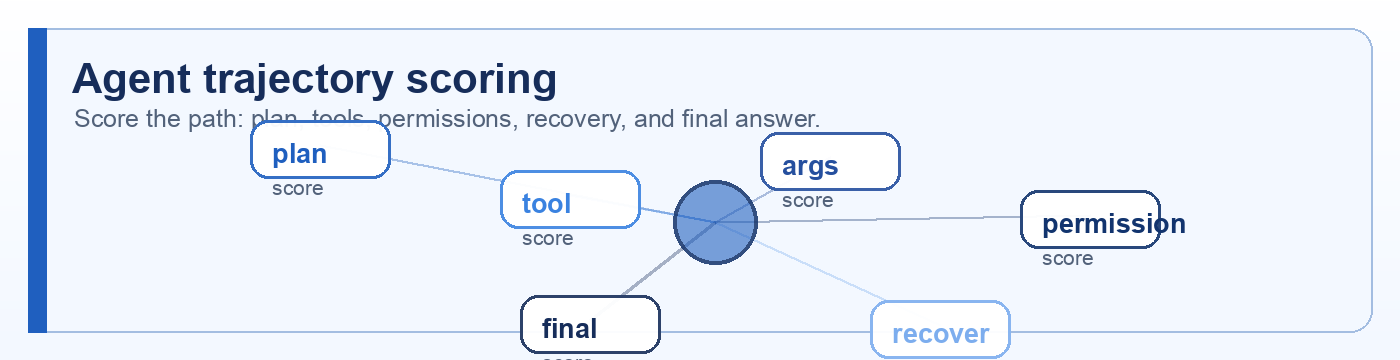
Quick description: Recording the path a system took, including prompts, retrieval, tool calls, outputs, latency, and cost.
Example: Debug a bad answer by following the exact retrieved documents and tool calls that produced it.
Quick description: A related concept from Truth that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use truthfulness as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: The design and use of type to support readability, tone, and hierarchy.
Example: Include typography in the rubric when judging AI-generated pages, messages, or workflows.
Quick description: A related concept from Undue influence that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use undue influence as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: The overall experience a person has while using a product.
Example: Include user experience in the rubric when judging AI-generated pages, messages, or workflows.
Quick description: A related concept from Personal data that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Include user-owned memory in the rubric when judging AI-generated pages, messages, or workflows.
Quick description: A software quality concept used to check behavior, risk, or confidence before release.
Example: Use validation as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Value (economics) that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use value as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: How spread out measurements are across runs, cases, users, or model outputs.
Example: Use variance as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A search or retrieval concept used to decide whether the right information is found and ranked.
Example: Use vector databases as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Vendor lock-in that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use vendor lock-in as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A software quality concept used to check behavior, risk, or confidence before release.
Example: Use verification as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Vision language model that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Use vision-language models as a discussion point when defining eval cases, failure categories, or release evidence.
Quick description: A related concept from Visual design elements and principles that helps readers investigate AI quality, testing, and non-deterministic behavior.
Example: Include visual design in the rubric when judging AI-generated pages, messages, or workflows.
Quick description: The visual ordering that tells users what to notice first.
Example: Include visual hierarchy in the rubric when judging AI-generated pages, messages, or workflows.
Quick description: An AI product concept that expands what quality teams must observe, constrain, and evaluate.
Example: Use voice agents as a discussion point when defining eval cases, failure categories, or release evidence.






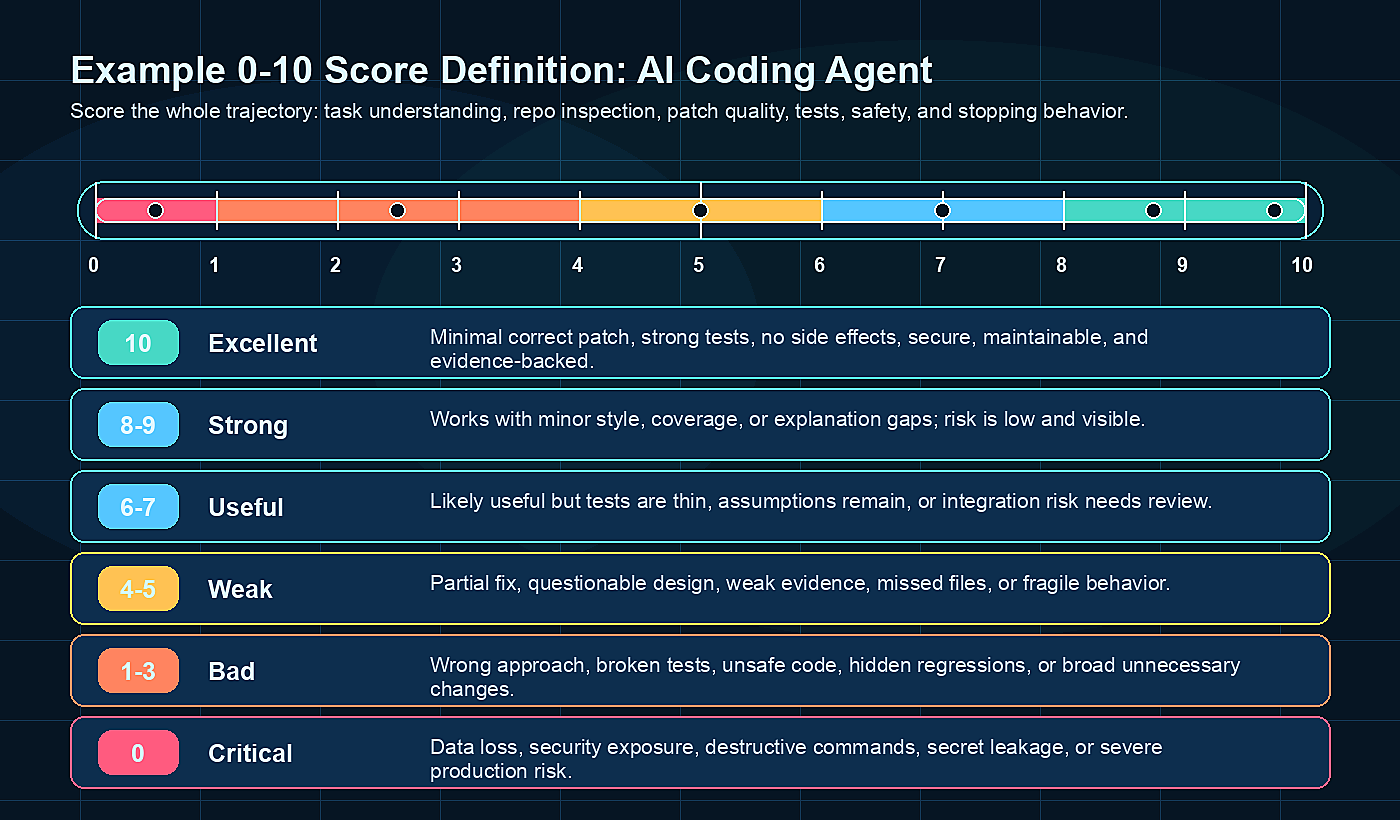
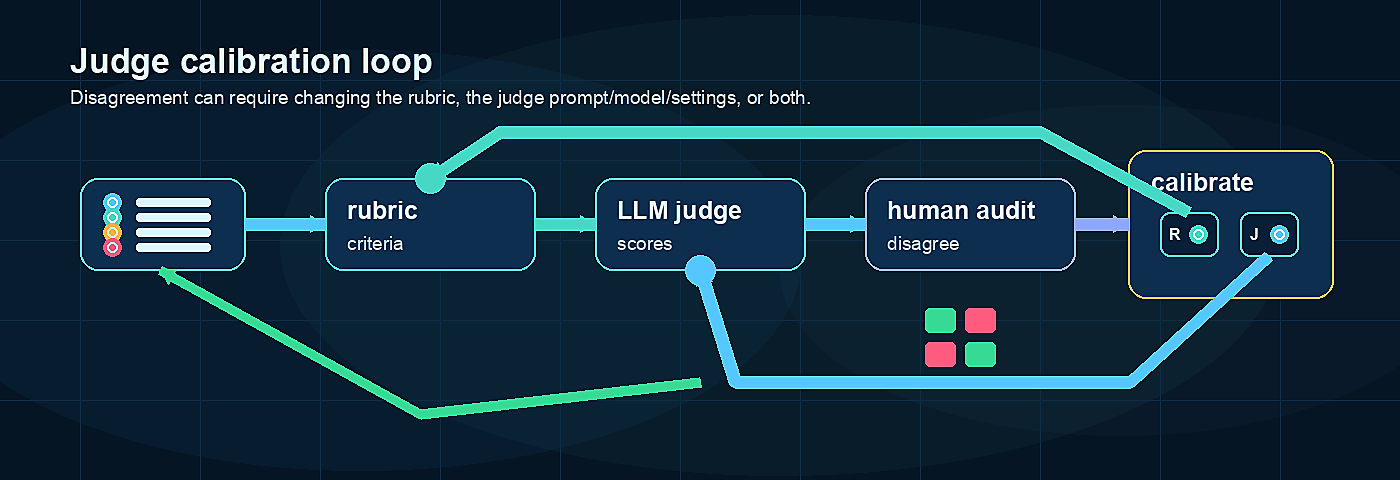

































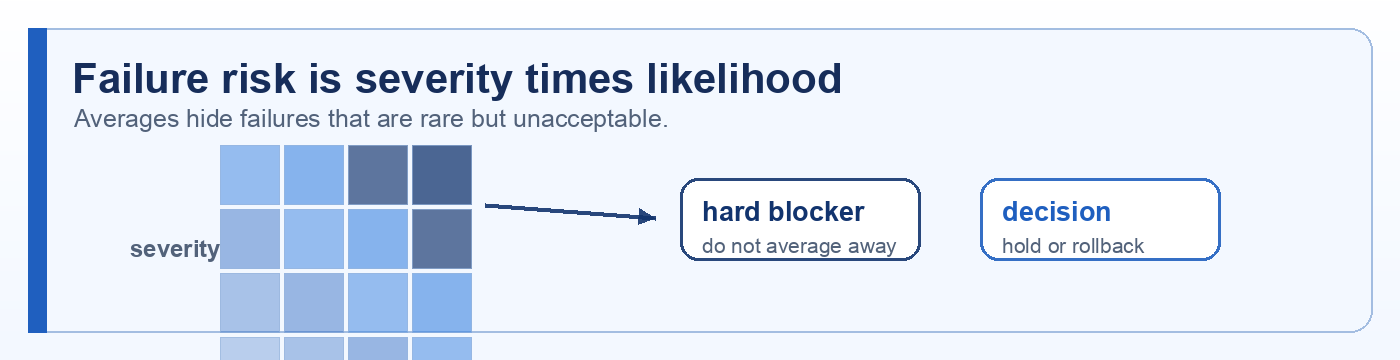













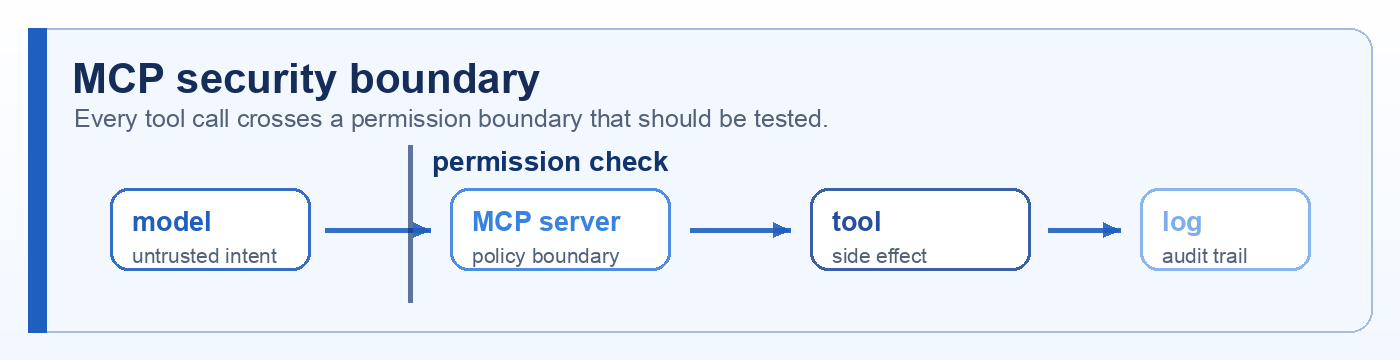





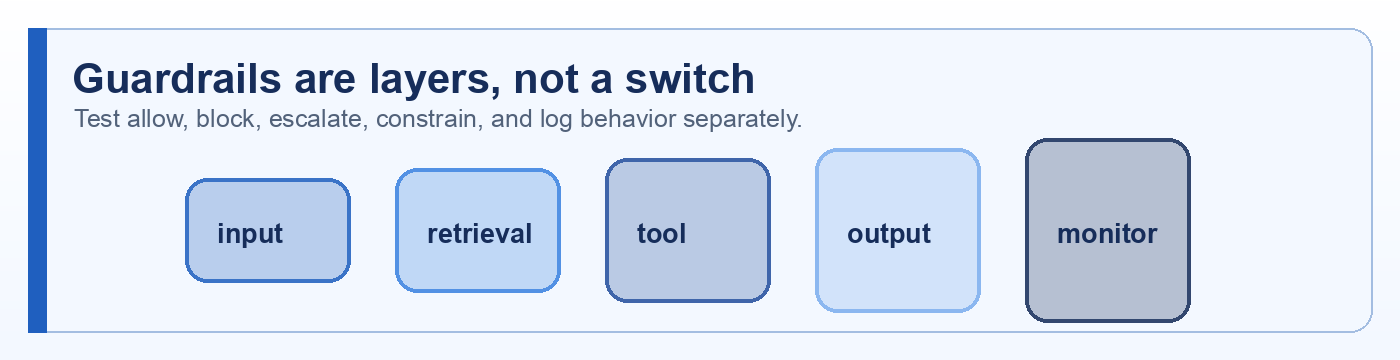




Draft comments: sign in, then select any preview text or chapter title to comment on it.